3 most important points
- 核心是注意力机制,之后是位置编码;此外只有前馈层、输出层、Norm 等功能层,Norm 优化方法可以注意
- 注意力公式: 其中注意力分数为 。本质上是对每个词,计算其余词与它的关联程度。而 就是需求的信息。 也就是,权重 * 信息
- Decoder 中,注意力机制通过 KV Cache 进行优化,因为推理过程输入是按字符循环输入的,所以记录字符的 KV 重复用于计算注意力;然而,当 sequence 特别长的时候,会占用过多内存,本质上是空间换时间
5 thoughts
- 注意到架构里有残差连接,所以注意力机制产生的是一个额外信息,而非全部信息;因此在交叉注意力时 Decoder 采取 Encoder 作为 V,采集自己需要的额外信息。所有的计算都是建立在需求额外信息上的,包括为什么要计算 vector 和自己的相关性。
- RNN 将整个输入序列压缩成一个固定长度的上下文向量,导致难以记住长序列的所有细节,且序列开头的信息在最终向量中可能被稀释;而自注意力一次性计算所有相关性,解决了 RNN 在长文本上的劣势。
- 多头自注意力机制关注不同方面的关联性
- Transformer 是 CNN 和 RNN 的上位替代;最重要的是能够全局建模且并行计算;控制 attention 的范围可以平衡复杂度和效果
- 对 self-attention 而言序列位置没有区别,位置编码补充了位置信息
Notes
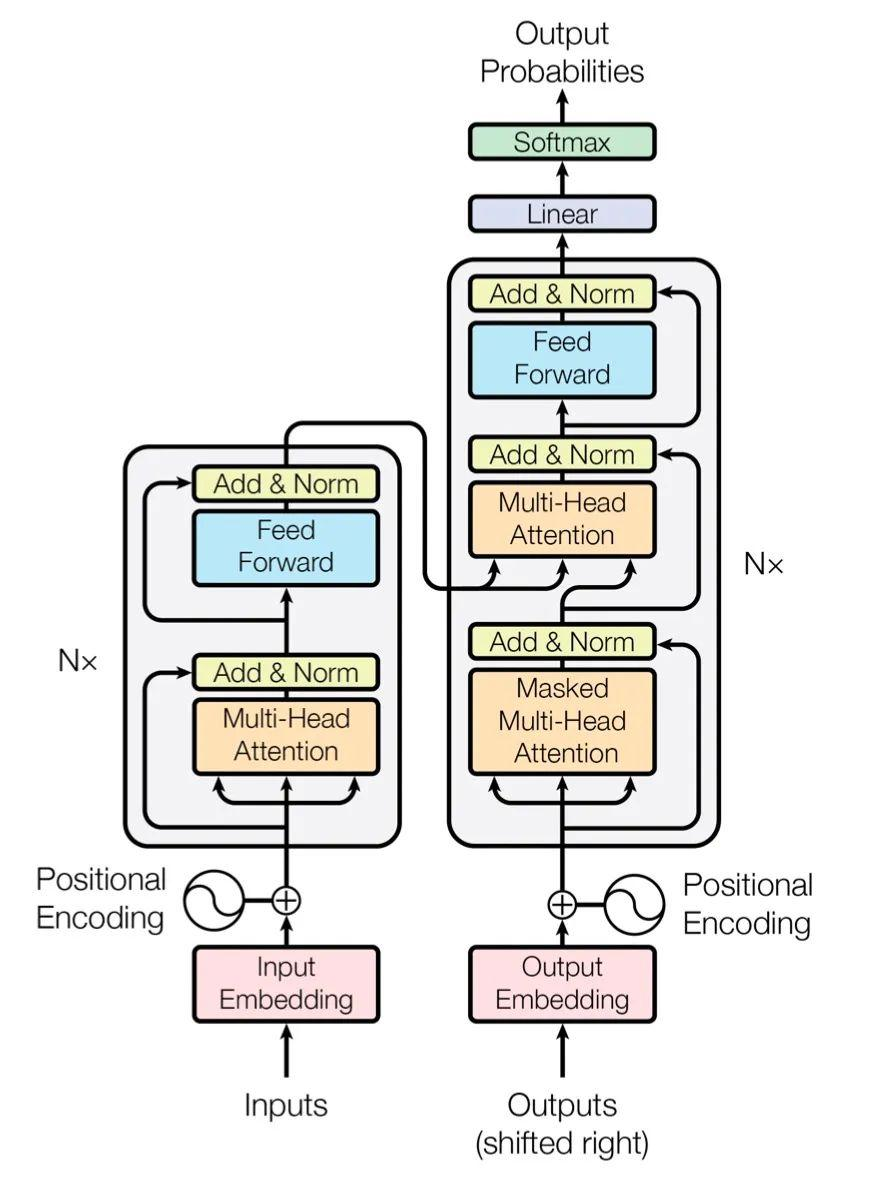
整体结构
Transformer 结构图
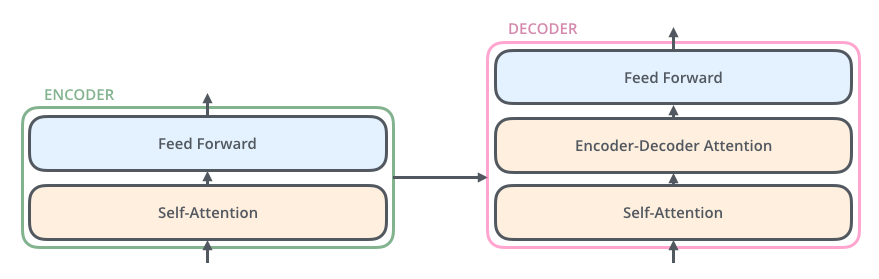
MultiHeadedAttentionPositionwiseFeedForwardPositionalEncodingEncoderLayerEncoderDecoder
Encoder 结构
def make_model(N=6, hidden_size=512, d_ff=2048, h=8, dropout=0.1):
attn = MultiHeadedAttention(h, hidden_size)
ff = PositionwiseFeedForward(hidden_size, d_ff, dropout)
position = PositionalEncoding(hidden_size, dropout)
model = Encoder(EncoderLayer(hidden_size, attn, ff, dropout), N)N:层数hidden_size:向量query,key,value的特征数量(MHA 中为d_model)d_ff:前馈层维度h:头数量dropout:dropout比率
class EncoderLayer(nn.Module):
def __init__(self, hidden_size, n_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadedAttention(n_heads, hidden_size, dropout)
self.feed_forward = PositionwiseFeedForward(hidden_size, d_ff, dropout)
self.sublayer = clones(SublayerConnection(hidden_size, dropout), 2)
self.size = hidden_size
def forward(self, x, mask=None, bias=None):
# 注意力层
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask=mask, bias=bias))
attn_weights = self.self_attn.get_attn()
# 前馈网络
x = self.sublayer[1](x, self.feed_forward)
return x, attn_weights # 返回注意力权重
class Encoder(nn.Module):
def __init__(self, hidden_size, n_layers, n_heads, d_ff, dropout):
super(Encoder, self).__init__()
layer = EncoderLayer(hidden_size, n_heads, d_ff, dropout)
self.layers = clones(layer, n_layers)
self.norm = LayerNorm(hidden_size)
def forward(self, x, mask=None, bias=None):
attn_weights = bias
for layer in self.layers:
x, attn_weights = layer(x, mask, bias=attn_weights)
x = self.norm(x)
if bias is None:
bias = torch.zeros_like(attn_weights)
return x, attn_weights, attn_weights - biasx:特征嵌入,已加上位置编码mask:Masked Self-Attention
前馈层
前馈层的作用
将 Multi-Head Attention 得到的向量再投影到一个更大的空间(论文里将空间放大了 4 倍),在那个大空间里可以更方便地提取需要的信息(使用 Relu 激活函数),最后再投影回 token 向量原来的空间 借鉴 SVM 来理解:SVM 对于比较复杂的问题通过将特征其投影到更高维的空间使得问题简单到一个超平面就能解决。这里 token 向量里的信息通过 Feed Forward Layer 被投影到更高维的空间,在高维空间里向量的各类信息彼此之间更容易区别。
- 两个线性层夹一个激活函数(
relu)
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))Norm 层
Norm 层的作用
它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后输出可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常慢。 因此把神经网络中隐藏层归一为标准正态分布,以起到加快训练速度,加速收敛的作用。 这个归一针对 Layer 进行,即同一个样本内计算均值和方差
SublayerConnection:在层之前加norm,之后加dropout,对注意力层和前馈层应用
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, feature_size, eps=1e-6):
super(LayerNorm, self).__init__()
# 调节因子,缩放参数a初始化为1,位移参数b初始化为0
self.a_2 = nn.Parameter(torch.ones(feature_size))
self.b_2 = nn.Parameter(torch.zeros(feature_size))
# 防止分母为0
self.eps = eps
def forward(self, x):
#对最后一个维度分别求均值和标准差
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2注意力机制
Self-Attention
注意力公式
其中, 被称为注意力分数;除以 以归一化
实现中,添加了 ,即:
注意,在算完各个头的 Attention 之后,还有: 其中 是用以融合各个头输出的一个线性输出层
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None, bias=None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value))] # (batch_size, n_head, n_node + n_token, K)
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout, bias=bias)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
def get_attn(self):
return self.attnd_k:每个头的特征数量,等于d_model // heads,其中//为整除- 步骤
- 将
x转换为向量query、key和value;x为(batch_size, n_node + n_token, hidden_size)- 分别过一个线性层:
l (x),维度不变,为(batch_size, n_node + n_token, hidden_size) - 展平:
l (x). View (nbatches, -1, self. H, self. D_k),即将最后一维分解,d_model => h x d_k,最终为(batch_size, n_node + n_token, h, d_k) - 维度交换:
transpose (1, 2),最终维度为(batch_size, h, n_node + n_token, d_k)
- 分别过一个线性层:
- 计算
Attention- 计算经过缩放的注意力分数 ,如高亮行所示;
key.Transpose (-2, -1)将最后两个维度交换,所以输出形状为(batch_size, n_head, n_node + n_token, n_node + n_token) - 如有
mask和bias,进行对应处理 softmax和dropout处理,得到最终注意力分数p_attn,在 MHA 中存储为self. Attn- 与
V相乘,得到最终的x
- 计算经过缩放的注意力分数 ,如高亮行所示;
- 连接多个头(将
x调整为输入时的形状),最后经过一个线性层(输出层),得到最终输出
- 将
def attention(query, key, value, mask=None, dropout=None, bias=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1))/math.sqrt(d_k) # 输出形状: (batch_size, n_head, n_node + n_token, n_node + n_token)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
if bias is not None:
scores = scores + bias
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attnMasked Self-Attention
掩码的作用
- 屏蔽掉无效的 padding 区域
- 屏蔽掉来自“未来”的信息
- Encoder 中的掩码主要是起到第一个作用
- Decoder 中的掩码则同时发挥着两种作用
- 传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入因此在训练过程中输入 t 时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t 时刻运算结束了,才能看到 t+1 时刻的词。
- 而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。
- Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可,之后再做 softmax,就能将 -inf 变为 0,得到的这个矩阵即为每个字之间的权重。
Masked Encoder-Decoder Attention
示意图
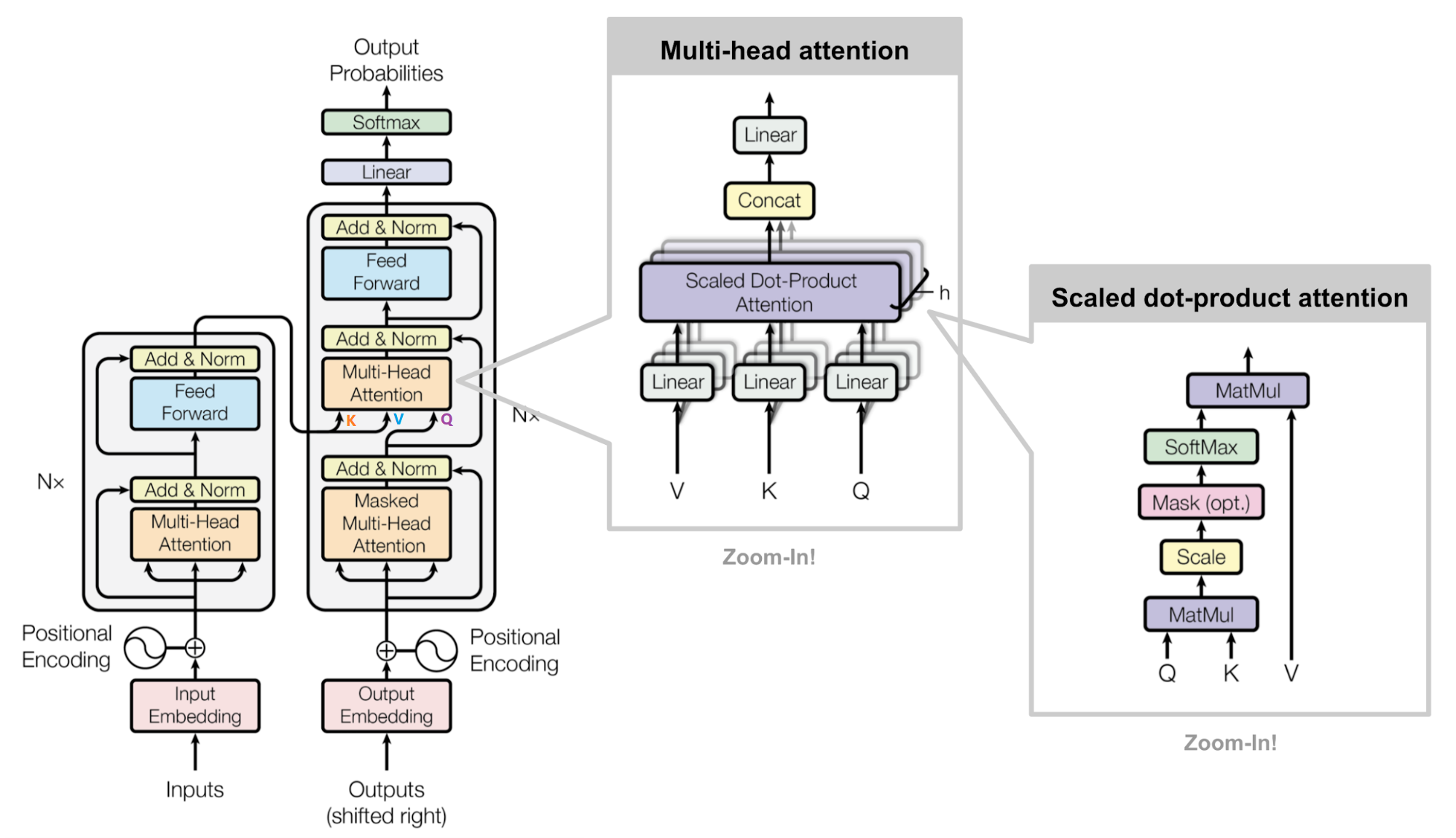
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的 为 Encoder 的输出, 为 Decoder 中 Masked Self-Attention 的输出
KV Cache
KV Cache 的作用
KV Cache 是一种关键的性能优化机制。它通过缓存已计算的 Key 和 Value 矩阵,避免在自回归生成过程中重复计算,从而显著提升推理效率(本质就是用空间换时间)。这种机制类似于人类思维中的短期记忆系统,使模型能够高效地利用历史信息。
KV Cache 是 Transformer 标配的推理加速功能,Transformer 官方 use_cache 这个参数默认是 True,但是它只能用于 Decoder 架构的模型,这是因为 Decoder 有 Causal Mask,在推理的时候前面已经生成的字符不需要与后面的字符产生 attention,从而使得前面已经计算的 K 和 V 可以缓存起来。
在推理(生成)过程中,字符是一个接一个输入 Decoder 的;Decoder 先接受一个起始字符 <s>,然后将推理结果循环输入,得到最终结果。
观察下面这个式子:
相当于是一次推理过程中的四次循环,也就是四次计算; 可以看到,计算过程中,、、 以及 、、 都在重复出现
使用 KV Cache 保存这些计算结果,即可进行重复利用; 每次计算,KV Cache 中都会加入一对新的 KV,所以实际上这是一种增量 KV 计算
示意图
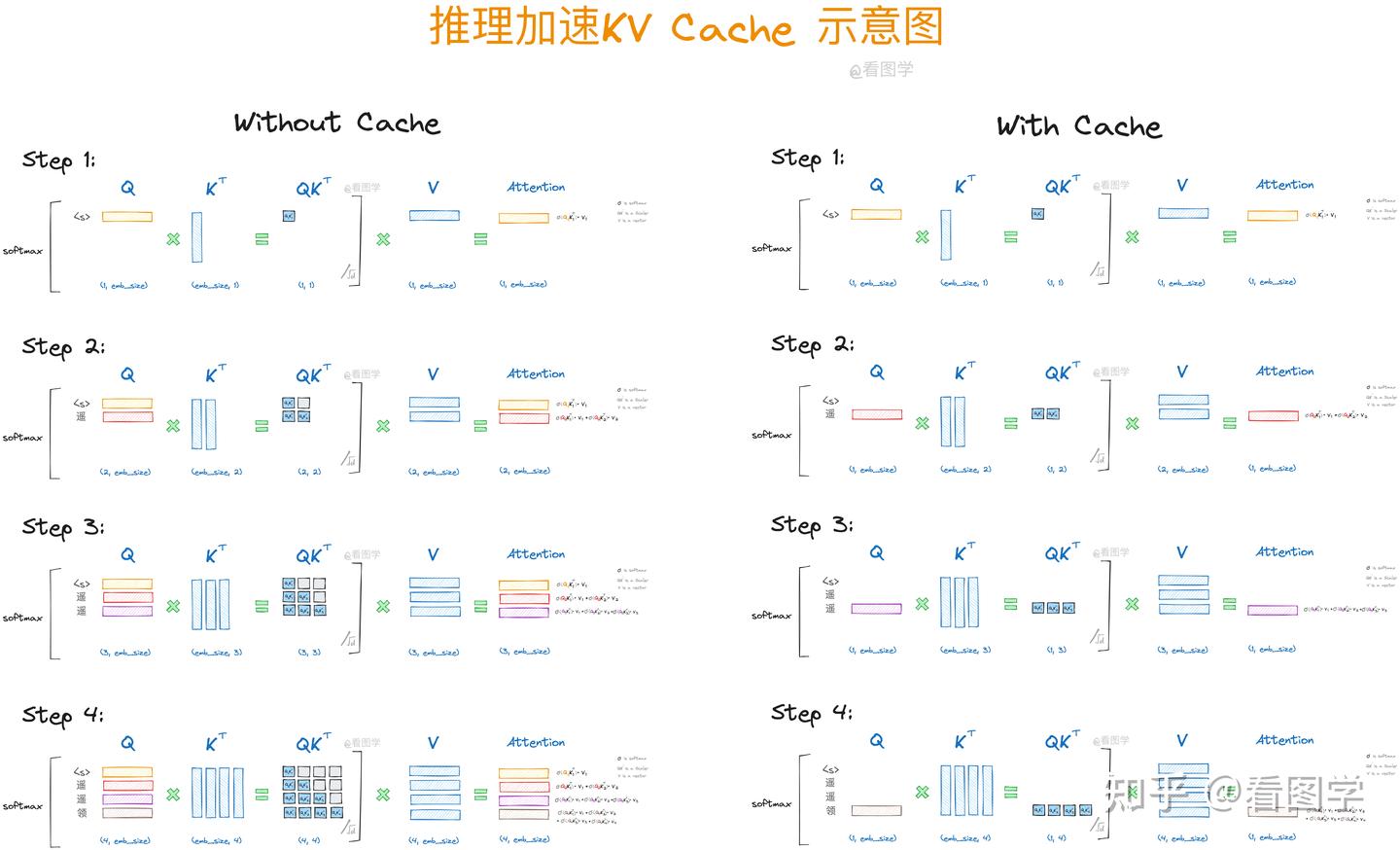
从图中可以看出,使用 Cache 之前, 对后续字符的注意力也一直在被计算(图中 灰色部分),这实际上是不需要的,因为推理过程中后续内容不可见——这就是 Causal Mask 的作用,因此计算冗余,所用部分只需要被记录。
# 如果这不是第一次计算
if layer_past is not None:
# 获取之前的KV
past_key, past_value = layer_past
# 进行concat,得到计算需要用的KV矩阵
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
# 记录当前KV,以便后续使用
if use_cache is True:
present = (key, value)
else:
present = None
# 注意力计算
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)Warning
当 sequence 特别长的时候,KV Cache 会占用过多内存
比如
batch_size=32, head=32, layer=32, dim_size=4096, seq_length=2048, type=float32,则需要占用的显存为2 * 32 * 4096 * 2048 * 32 * 4 / 1024 / 1024 / 1024 / 1024 = 64G。
时间复杂度
时间复杂度分析
Self-Attention 时间复杂度: ,这里, 是序列的长度, 是
embedding的维度。 Multi-Head Attention 时间复杂度:
- 相似度计算:可以看作大小为 和 的两个矩阵相乘:,得到一个 的矩阵
- softmax:就是直接计算了,时间复杂度为:
- 加权平均:可以看作大小为 和 的两个矩阵相乘:,得到一个 的矩阵
- 多头实现:通过 transposes and reshapes,用矩阵乘法来完成
- 和 的维度都是
- 这样点积可以看作大小为 和 的两个张量相乘,得到一个 的矩阵,其实就相当于 和 的两个矩阵相乘,做了 次,时间复杂度是:
- 因此 Multi-Head Attention 时间复杂度也是 ,复杂度相较单头并没有变化,主要还是 transposes and reshapes 的操作,相当于把一个大矩阵相乘变成了多个小矩阵的相乘。
位置编码
Sin-cos 位置编码
Transformer 是纯注意力机制,不像 RNN/CNN 有天然的序列结构,所以需要人工加入位置信息来让模型知道每个词的顺序。
位置编码的核心目标
在不使用循环或卷积的前提下,让每个 token 带上自己的位置信息,同时保留可泛化能力(如支持长度外推)。
常见位置编码公式
具体来说,对于位置 和维度 ,位置编码的第 维度可以用以下公式表示: 其中 是位置编码的总维度, 是位置索引, 是维度索引。
- 为什么使用 sin 和 cos 作为位置编码
- 可以证明,位置编码的内积是一个只与相对位置关系相关的定值,即
- 为什么奇数位和偶数位需要用不同的函数
- 通过交替使用 和 函数,可以确保每个位置的编码向量在所有维度上都是唯一的,并且能够保留位置信息。
频率因子
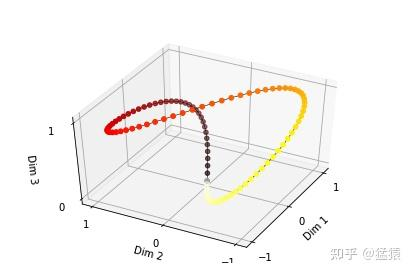
通过频率引自来控制 sin 函数的波长,频率不断减小,则波长不断变大,此时 sin 函数对 t 的变动越不敏感,类似于二进制编码,每一位上都是 0 和 1 的交互,越往低位走,交互的频率越慢。
由于 sin 是周期函数,因此从纵向来看,如果函数的频率偏大,引起波长偏短,则不同 t 下的位置向量可能出现重合的情况。比如在下图中 (d_model = 3),图中的点表示每个 token 的位置向量,颜色越深,token 的位置越往后,在频率偏大的情况下,位置向量点连成了一个闭环,靠前位置(黄色)和靠后位置(棕黑色)竟然靠得非常近:
为了避免这种情况,我们尽量将函数的波长拉长。一种简单的解决办法是同一把所有的频率都设成一个非常小的值。因此在 transformer 的论文中,采用了 这个频率。
{kind=link}
{kind=link}
原理解析
为什么需要保证位置编码的内积只与 有关?
因为我们希望 注意力机制能识别“相对位置”而不是“绝对位置”,而内积是注意力的核心操作。
如果内积只和距离有关,那注意力机制就能学会“两个词之间的相对关系”,而不是死记它们在句子里的绝对位置。
目标 为什么位置编码内积只与 k 有关有助于实现它? 相对位置信息建模 因为 Attention 的输入是向量内积,只有与 k 相关才能学习“距离” 泛化到更长序列 不依赖绝对位置,才能处理长度不同的新数据 保留语义依赖结构 相对位置能表达“动词-主语”、“定语-中心词”的相对语法结构
证明:在输入 上添加位置编码后,再与 、 相乘,计算注意力的点积时,位置编码之间的 dot product 进入注意力分数,并且它是否只与位置差 有关,会直接影响模型是否能感知相对位置信息。
- 设定变量
- :原始输入的 embedding( 是序列长度, 是维度)
- :位置编码(按论文方法构造)
- :注意力中用于变换的权重矩阵
- 注意力分数:
- 展开公式
- 将:
- 代入注意力分数:
- 使用内积线性性展开:
- 拆解四项:
- :原始内容与原始内容之间的 dot(semantic attention)
- :语义信息关注目标位置的“位置信息”
- :自己的位置信息关注目标内容
- :位置对位置的 dot product,完全取决于 i 和 j
- 含义分析
- 如果 是标准 sin-cos 编码,并且我们认为 (即不改变方向),则:
- 这个内积只与 k = i - j(位置差)有关!
- 加了位置编码后,注意力得分中的一个关键部分:
- 所以,即使没有显式建模相对位置,transformer 也能隐式学会距离感。
- 如果 是标准 sin-cos 编码,并且我们认为 (即不改变方向),则:
- 总结
- 注意力打分展开后包含: 其中,位置之间的内积只与距离 k 有关 ⇒ 成为模型感知相对位置的关键机制。
内积计算示例
使用 位置编码,即假设 的情况
0 1 2 3 0 1 2 3
具体数学证明(三角恒等式):\begin{align*} PE_t^T * PE_{t+\Delta t} &= \sum_{i=0}^{\frac{d_{model}-1}{2}} \left[ \sin(w_i t) \sin(w_i (t+\Delta t)) + \cos(w_i t) \cos(w_i (t+\Delta t)) \right] \\ &= \sum_{i=0}^{\frac{d_{model}-1}{2}} \cos(w_i (t - (t + \Delta t))) \\ &= \sum_{i=0}^{\frac{d_{model}-1}{2}} \cos(w_i \Delta t) \end{align*}
代码展示
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 创建一个足够大的位置编码矩阵
# 注意下面代码的计算方式与公式中给出的是不同的,但是是等价的
# 这样计算是为了避免中间的数值计算结果超出float的范围,
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 填充位置编码矩阵
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度
# 增加一个批次维度
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
# 将位置编码添加到输入张量x中
x = x + self.pe[:x.size(0), :]
return xpe = torch.Zeros (max_len, d_model):创建一个形状为(max_len, d_model)的零矩阵,用于存储位置编码。position = torch.Arange (0, max_len, dtype=torch. Float). Unsqueeze (1):生成一个从 0 到max_len的位置索引向量,并通过unsqueeze (1)将其扩展为二维张量,形状为(max_len, 1)。div_term = torch.Exp (torch.Arange (0, d_model, 2). Float () * (-math.Log (10000.0) / d_model)):计算分母部分,用于调整频率torch.Arange (0, d_model, 2)生成偶数维度索引-math.Log (10000.0) / d_model是频率衰减因子
权重共享
- Encoder 和 Decoder 间的 Embedding 层权重共享
- 含义:Transformer 最初被用来执行翻译任务,Encoder 的输入是源语言,Decoder 的输入是目标语言;共享 Embedding 层权重相当于两种语言共用一张大词表
- 优点:共同出现的词(比如说数字、标点符号)能够更好地表示;BPE 得到的 subword(类似于词根)能够共享语义
- 缺点:使词表数量增大,增加 softmax 的计算时间
- Decoder 中 Embedding 层和 FC 层权重共享
- FC 层:应该指的是 Decoder 最后的 Linear 层和 Softmax 层,用于解码;
- 原因:Embedding 通过 onehot 取到词对应的 embedding 向量,FC 层通过向量进行 softmax 得到它可能是某个词的概率以预测它是某个词;类似于互为逆过程
- 优点:这样的权重共享可以减少参数的数量,加快收敛
Related
Reference
- 代码实现来自 Final Year Project 实际上就是原 Transfromer 代码
- Transformer 入门教程,写得很清楚
- 位置编码详细推理 这个也是一整个系列,比较基础入门
- 探秘Transformer系列 特别细致,每个模块都有后续优化的介绍,建议后期再看
- The Annotated Transformer 代码详解
- 中文代码解析 上一条的中文翻译
- kv cache图解 有很多图