3 most important points
- 开源,且性能不输顶级闭源模型
- 结构优化包括:RoPE,Pre-Norm,RMSNorm,GQA,SwiGLU
5 thoughts
Notes
引言
LLaMA 65B 是由 Meta AI(原 Facebook AI)发布并宣布开源的真正意义上的千亿级别大语言模型,发布之初(2023 年 2 月 24 日)曾引起不小的轰动。LLaMA 的横空出世,更像是模型大战中一个搅局者。虽然它的效果(performance)和 GPT-4 仍存在差距,但 GPT-4 毕竟是闭源的商业模型,LLaMA 系列的开源给了世界上其他团队研究和使用千亿大语言模型的机会。
特别是 LLaMA 3.1 405B,在多项测试中超越 GPT-4o。
- 具有 128k 上下文,多语言,良好的代码生成能力,复杂推理能力,及工具使用能力
- 能够轻松集成
- 开源,允许进行微调,蒸馏到其他模型中,及在任何地方部署
Tip
Llama 经历了 3 次重要的架构更新:
- 版本 1 对原始的 Transformer 架构进行了多项改进,包括 Norm、激活函数和位置编码
- 版本 2 在大模型中引入了分组查询注意力(GQA)机制。
- 版本 3 将 GQA 扩展到了小模型,同时引入了更高效的分词器,还扩大了词汇量。
- 版本 3.1 并未对核心架构做出调整,主要的变化在于训练数据的清洗、上下文长度的增加以及对更多语言的支持。
- LLaMA-1
- 规模:65B
- 数据量:1.4T
- 创新点:
- Pre-Norm (受 GPT-3 启发)
- 使用 RMSNorm
- LN 中包含平移和缩放不变性,RMSNorm 去除平移,只保留缩放
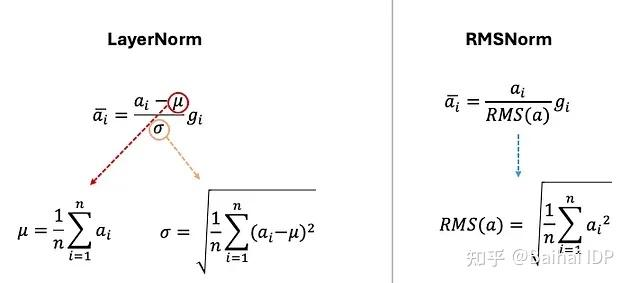 这是因为发现 LN 的优势在于适应缩放,而非适应均值变化
这是因为发现 LN 的优势在于适应缩放,而非适应均值变化 - 效果相当,而运算效率显著提升
- LN 中包含平移和缩放不变性,RMSNorm 去除平移,只保留缩放
- SwiGLU 激活函数(受 PaLM 启发)代替 ReLU;具体见激活函数
- 旋转位置编码 RoPE(受 GPTNeo 启发)
- 问题:绝对位置编码已经解决了 Transformer 不区分顺序的问题,但它生成的位置编码是相互独立的,没有考虑到序列中单词之间的相对位置关系
- 解决:RoPE 能够解决上述问题,它通过将序列中的每个位置转换成词嵌入的旋转变量来模拟单词间的相对位置关系
- 好处:即便在原句中增加更多词汇,单词之间的相对距离也能得到保持
- LLaMA-2
- 规模:70B
- 数据量:2T
- 创新点:
- 分组查询注意力机制(Grouped-Query Attention,GQA),平衡效率和性能
- 问题:由于需要大量内存来加载所有的注意力头的 queries、keys 和 values ,MHA 成为了 Transformer 的性能瓶颈
- 解决:将查询值(query values)分为 G 组(GQA-G),每组共享一个键和值头(key and value head)
- 好处:与 MQA 相比,这种更为温和的缩减方式在提升推理速度的同时,也降低了解码过程中的内存需求,且模型质量更接近 MHA,速度几乎与 MQA 持平
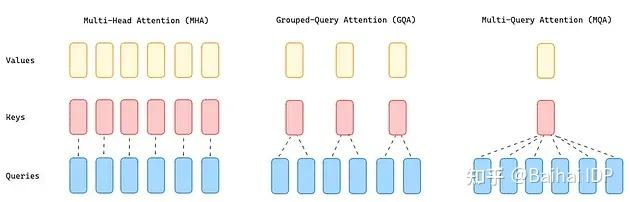
- 分组查询注意力机制(Grouped-Query Attention,GQA),平衡效率和性能
- LLaMA-3
- 规模:405B
- 数据量:15T
- 创新点:
- 将分词器从 Sentence Piece 更换为 OpenAI 模型所采用的 TikToken
- 上下文长度显著提升