3 most important points
- GPT 系列结构上的创新,包括 2 的 Pre-Norm,3 的 Sparse Attention(弃用)
- 主要创新是训练方法上的:微调→零样本学习→少样本学习;特殊标记→Prompt→Instruction→RLHF;数据处理
- 最最重要的是数据规模和模型规模超进化
5 thoughts
- 力大砖飞的代表作?印证了数据的重要性(多样性,清洗,对齐)
Notes
GPT-1
架构图
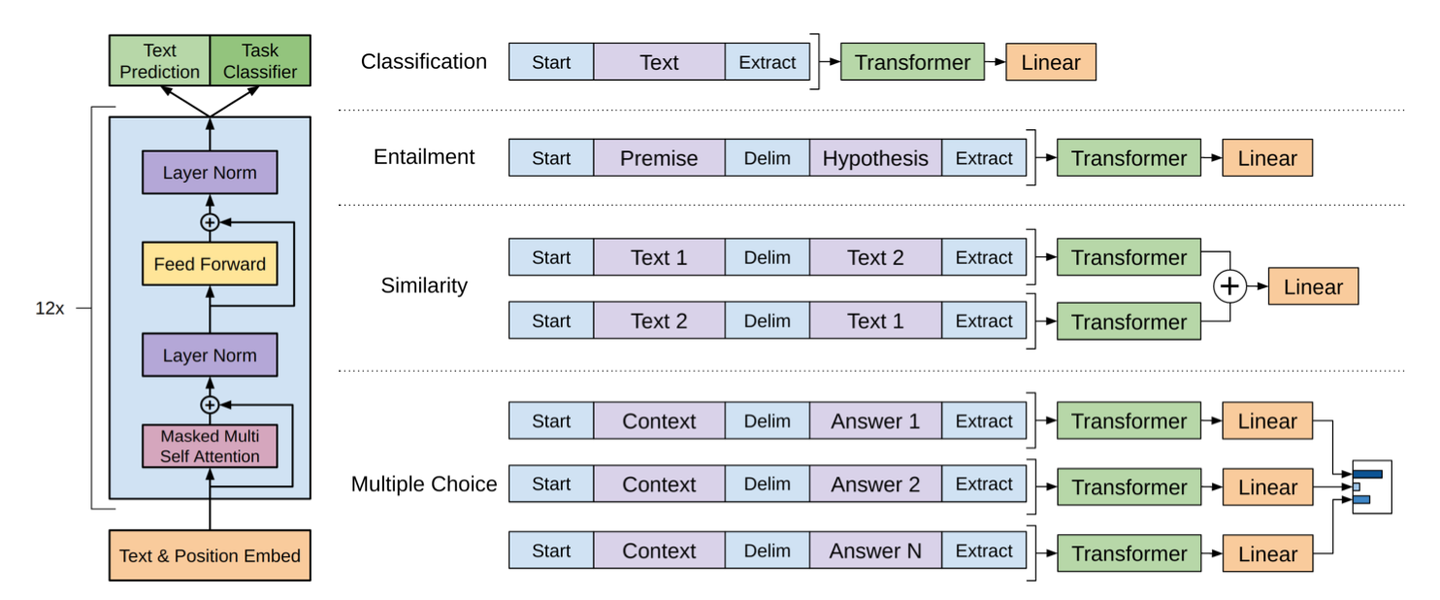
- 规模:117M,12 层,隐藏层维度 768
- 结构:
- Transformer Decoder 去掉交叉注意力模块
- 数据量:5GB
- 训练:
- 预训练:
- 自监督学习
- 自回归模式,给定前 N-1 个词预测第 N 个,串行循环输入 相应的,非自回归是平行运算,一次性生成所有输出
- 目标函数:
- :未标注的文本语料
- :第 个词
- :上下文窗口的大小(即当前词基于前 个词预测)
- :模型参数
- 微调:
- 有监督学习
- 新添加线性层从头训练,其它参数微调
- 目标函数:预训练的目标函数与下游任务的目标函数加权求和
- 预训练:
- 创新点:
- 系统性地验证了预训练-微调范式(基于 Transformer 解码器)在 NLP 领域的有效性
- 引入统一的任务输入格式,通过在输入文本中添加特殊标记及拼接文本,将不同下游任务的输入统一转换为连续序列的形式,使预训练模型能够复用
- 开始词元(Start Token): ,表示序列起始。
- 结束词元(End Token): ,表示序列结束。
- 分隔词元(Delimiter Token): $$$,用于分隔子序列,例如前提句和假设句,问题和答案。
GPT-2
- 规模:1542M,48 层,隐藏层维度 1600
- 结构:
- Layer Norm 提前到每个自注意力和 FFN 前,利于稳定优化;同时在最后的自注意力模块后增加额外的 LN
- 残差权重初始化,采用了 的权重缩放因子,其中 是残差层的深度 在 Pre-LN 架构中,LayerNorm 在前面,残差路径“裸露”,方差容易层层积累;缩放防止深层残差叠加导致参数激活或梯度过大,保持网络在层数增大时的稳定性
为什么 Pre-LN 有利于稳定优化?
在 Transformer 层数大于 12 层时,Post-LN 架构会出现训练不稳定:
- 因为残差连接在 LayerNorm 之后,梯度要经过很多层的归一化操作,从而改变梯度的尺度,使得深层梯度信号衰减
- 导致需要非常小的学习率或 warm-up,否则容易梯度爆炸或优化停滞
相对来说,Pre-LN 允许残差连接直接绕过 LayerNorm,梯度可以不被归一化操作干扰地回传,从而缓解梯度消失,使得训练更稳定。
- 不需要很长的 warm-up
- 可以使用更大的学习率
- 模型可以更深(GPT-2 甚至上百层时仍然可训练)
在此之后有多篇论文系统或定量证明了 Pre-LN 的优势。
实践结论:
模型 LayerNorm 位置 备注 Transformer (2017) Post-LN 训练浅层模型可行 GPT-1 Post-LN 容易不稳定 GPT-2 / GPT-3 / GPT-4 Pre-LN 标准配置 T5 v1 Post-LN 后来改进为 v1.1 Pre-LN LLaMA / Falcon / Mistral 等 Pre-LN 统一采用
- 数据量:40GB
- 创新点:
- Zero-shot Learning 零样本学习,无需微调
- 不再引入特殊符号,采用自然输入格式,也就是后来的 Prompt 这和 T5 一致
GPT-3
- 规模:175B,96 层,隐藏层维度 12888
- 结构:
- 交替使用密集(Dense)和局部带状稀疏注意力(Locally Banded Sparse Attention)使用,减少计算量
稀疏注意力
- 标准 attention 复杂度:
- 稀疏 attention 复杂度: 或更低,如
- 核心思想:不再让每个 token 注意所有前面的 token,而只注意“部分位置”(如局部块 + 周期性 stride 连接)

- Local attention:只看最近 个 token;
- Strided attention:每隔 个 token 看一次;
- Fixed pattern / block-sparse attention:分块后块内 dense、块间稀疏。
- 实测结果:
- 小模型上稀疏注意力的节省明显(大约节省 30%~40% FLOPs)
- 性能略有下降,损失了少量困惑度性能 PPL(1~3%)
- 在大模型上,性能损失会放大,因此 GPT-3 最终选择全部使用 dense attention
模型规模 注意力类型 序列长度 训练速度提升 困惑度变化 125M / 350M Sparse 2048 ~1.5× 加速 略劣(+1–2 困惑度点) 1.3B 以上 Dense 2048 baseline 最优
- 后续研究:
- 稀疏注意力虽然节省显存和计算,但在语言建模任务(尤其是 GPT 类型的自回归建模)上效果略差
- 原因:语言模型对远程依赖敏感,而稀疏模式可能遗漏关键上下文
- 后续模型(GPT-NeoX, PaLM, LLaMA)都回归了 dense attention
后来的解决方案
FlashAttention(2022),通过更高效的 CUDA kernel 实现 dense attention;既保留 dense 的信息完整性,又大幅降低显存与计算 overhead
- 数据量:45TB
- 自动过滤:自动打分,文档得分越高越容易保留,低分文档也有一定概率(维持多样性)
- 模糊去重:检测文档间相似度,对相似度较高的文档进行删除;但仍然存在数据泄露(少量测试集内容被模型见过)
- 创新点:
- 引入实例样本,即少样本学习 Few-shot Learning,在 Prompt 中加入少量样本告诉模型需要完成的具体任务,无需微调;数量越多,效果越好
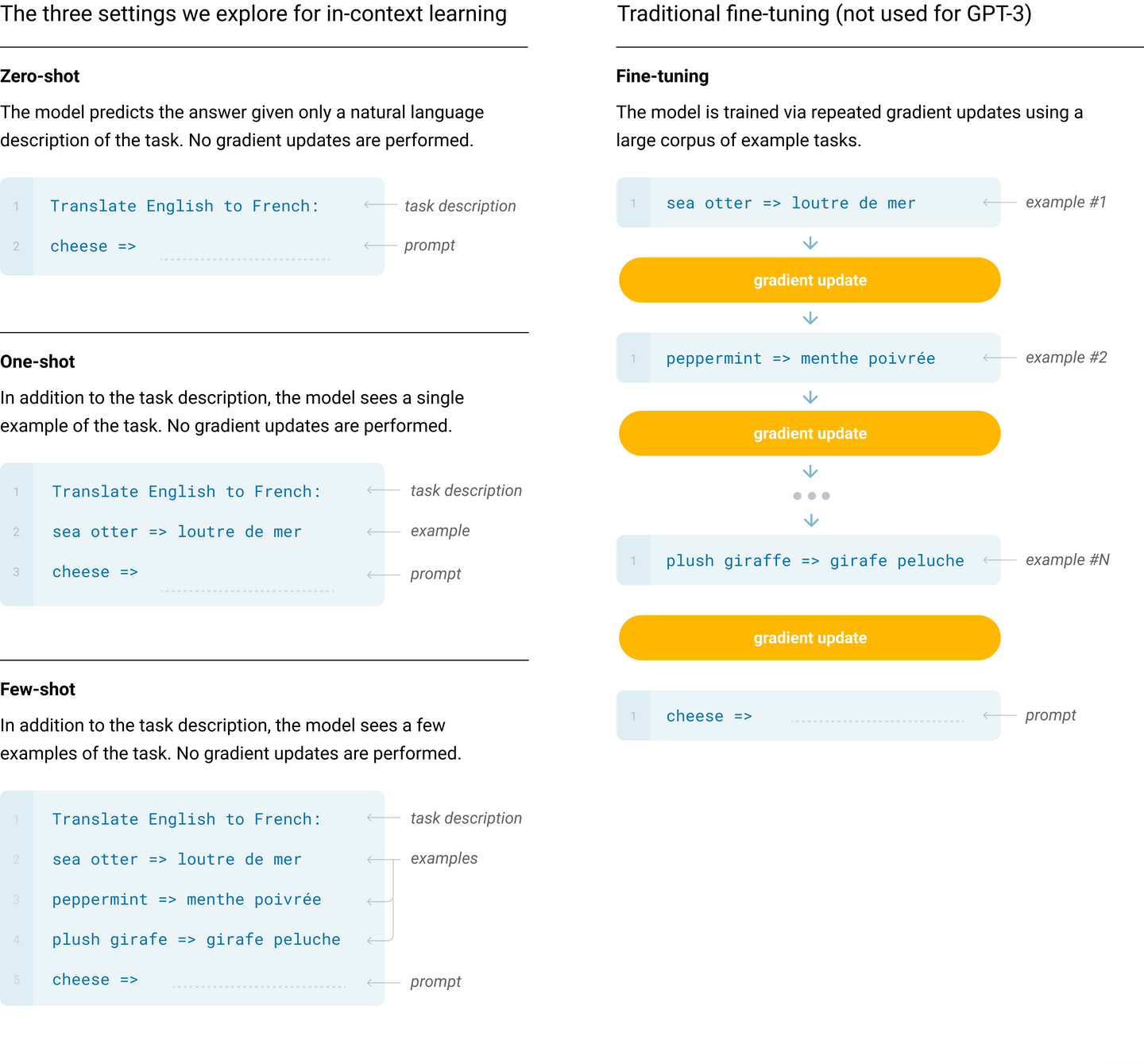 Zero-Shot、One-Shot 和 Few-Shot 本质上是 In-Context Learning 的三种不同设置(见上图左上角的叙述),其区别仅在于上下文提示中任务样本的数量。In-Context Learning 不更新参数。
Zero-Shot、One-Shot 和 Few-Shot 本质上是 In-Context Learning 的三种不同设置(见上图左上角的叙述),其区别仅在于上下文提示中任务样本的数量。In-Context Learning 不更新参数。 - 验证 Scaling-law:增加模型的规模和计算量会显著降低语言建模损失,甚至这个趋势在扩展了两个数量级后一样成立,只有轻微的偏离(也是 OpenAI 提出的)
- Emergent ability 涌现能力:当模型规模大到一定程度(60B),模型能力出现飞跃
- 引入实例样本,即少样本学习 Few-shot Learning,在 Prompt 中加入少量样本告诉模型需要完成的具体任务,无需微调;数量越多,效果越好
- 局限性:
- 逻辑:生成长文本出现语义重复、失去连贯性、前后自相矛盾
- 物理:准确来说是“常识物理”容易出错,比如“如果把奶酪放进冰箱会不会融化?”
- 理解:
- 因为采用的是解码器架构,所以在部分需要双向理解的任务上表现一般,比如说完形填空,又或者两句话之间互相比较,以及阅读理解的任务
- 在训练时默认“平等地”对待所有词(token),缺乏对词的重要性的衡量
- 缺乏多模态信息
- 有效性:样本有效性低,预训练所需的数据量远超过人类一生中所能阅读的文本量
- 成本:模型参数规模太大导致推理费用昂贵,可以蒸馏出更小规模子模型用于特定任务
- 问题:
- 不清楚在少样本的设置下,模型是在“学新技能”还是在“检索已有知识”
- 缺乏可解释性、预测校准(calibration)不佳,性能方差比人类高很多,并且带有训练数据的偏见
GPT-4
- 规模 & 结构 & 数据量:(技术细节不开源)
- 训练:
- Reinforcement Learning With Human Feedback (RLHF):用于对齐人类偏好,即让基础模型知道用户实际上需要它来做什么;属于微调
- 关注点:
- 损失预测
- 在小模型上可以用幂律关系(Power Law)来很好地拟合最终损失(Loss)与训练所需的计算量(Compute)之间的关系:,其中 为计算量,其余为需要拟合的参数
- 能够在仅有 1/1000 到 1/10000 计算量的小模型上准确地预测 GPT-4 的某些性能表现,从而可以先在小模型上进行快速验证和调优,最后再应用到大模型上,减少时间和算力耗费
- 能力预测
- 用小模型的训练结果进行幂律外推,成功预测了 GPT-4 在 HumanEval 部分子集上的通过率
- Inverse Scaling Prize
- 模型规模越大,表现越差的任务;但是,GPT-4 达到了 100% 的准确率
- 性能表现:
- 在现实场景中还不如人类,但在各种专业和学术基准测试中有了显著提升,经常超越大多数人类考生
- 在数学、编程和文学方面表现较差
- 作者认为模型的考试能力似乎主要来自于预训练过程,与后期的人类反馈微调(RLHF)关系不大
- 多模态能力:
- 能够处理图像和文本输入,并生成文本输出
- 损失预测
RHLF
- RLHF(Reinforcement Learning from Human Feedback):用强化学习让模型“更符合人类偏好”
- 效果:
- 生成更有礼貌、简介、符合问答预期
- 缺点:
- 训练成本极高(人工标注 + PPO)
- 奖励模型容易引入偏见
- RL 阶段可能让模型“过于保守”
阶段 名称 作用 Step 1:监督微调(SFT) 用人工编写的高质量问答数据,微调 GPT-3 教模型生成“像人说的”回答 Step 2:奖励模型(RM)训练 标注者对模型生成的多个回答进行排序 训练一个奖励模型 预测人类偏好 Step 3:强化学习优化(PPO) 用 PPO 或类似算法优化 GPT,使其输出最大化 RM 得分 让模型学会偏好“高分回答”
Instruction Tuning 与 Prompt
- Instruction Tuning(指令微调):用监督数据教模型“理解指令、遵循任务要求”
- 做法:在大规模、多任务指令数据集上进行监督微调
特征 GPT-2 的 Prompt GPT-3.5/4 的 Instruction Tuning 训练目标 语言建模(next token prediction) 指令-响应监督微调 是否理解“指令” ❌ 没有,靠上下文猜 ✅ 显式学习 是否需要任务模板 ✅ 需要手工设计 prompt ❌ 模型能直接理解自然指令 泛化能力 弱(模板变化会失效) 强(zero-shot / few-shot) 代表模型 GPT-2, GPT-3(基础模型) InstructGPT, ChatGPT, GPT-4 人类反馈 无 可进一步结合 RLHF
Example
阶段 核心机制 关键词 GPT-2 (2019) Prompt Engineering “靠提示诱导” GPT-3 (2020) Few-shot / Zero-shot prompting “用例子教模型” InstructGPT (2022) Instruction Tuning + RLHF “模型学懂任务” GPT-4 (2023) 大规模多任务指令调优 + 多模态 “模型理解人类意图”
- 局限性:
- 幻觉 Hallucination
- 上下文窗口有限
- 预训练数据阶段(训练数据大多截至 2021 年 9 月左右)
- 低级推理错误,且容易轻信用户明显错误的说法
- 存在偏见或歧视性内容
- 在经历指令微调(Instructed Tuning)和 RLHF 等后训练之后,校准度明显下降,更容易出现“过度自信”