3 most important points
- Decoder-Only 是主流架构; Encoder-Only 生成能力缺失,且限于句子和段落级别,发展缓慢
- Encoder-Decoder 适合做需要理解输入(即有条件)后的输出相关任务,如机器翻译,问答系统,但计算复杂度更高,且泛化性能类似
- 本篇提到的所有模型,后期基本都没有结构上的改进了,在卷数据量和数据清洗
5 thoughts
- BERT 和 Transformer 差别还是有一些的,GPT 可以说是几乎没有差别,只是去掉了一个模块,做了一些小改动,亮点全在框架和思路——敏锐发现自监督学习的潜力,开发少样本学习和 In-context Learning,是现在 LLM 的基础
Notes
Evolutionary Tree of LLMs
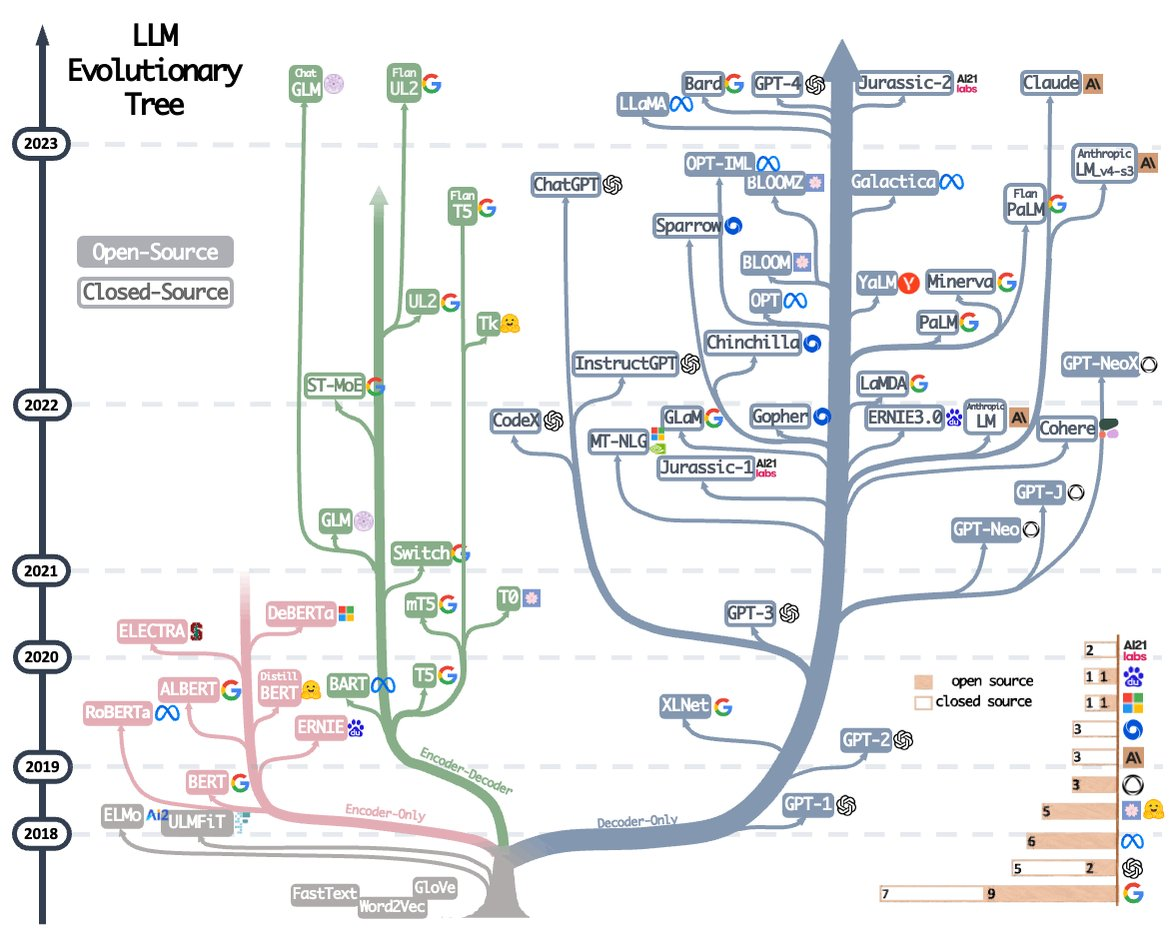
来自 GPT
路线 代表模型 主要创新 堆规模派(Scaling law) GPT 系列、Claude、Gemini 数据、指令调优、对齐机制 结构创新派(Architecture) RWKV、Mamba、RetNet、Mixtral 注意力替代、长上下文、专家机制 算法优化派(Efficiency) FlashAttention、LoRA、QLoRA 更高效的训练与推理 范式探索派(Agent 化) Gemini、GPT-4o 多模态融合、推理与工具使用一体化
Encoder-Only
- BERT
- 优点
- 通过 MLM 任务获取到上下文相关的双向特征表示
- 可以通过微调,将预训练好的模型迅速迁移到各种下游任务
- 适合各种自然语言理解 NLU 任务
- 缺点
- 只使用了 transformer 编码器部分,没有进行自回归预训练,且架构上缺少解码器,不适合直接处理自然语言生成 NLG 任务,如生成对话,文章摘要,机器翻译
- 只适合处理句子和段落级别的任务,不适合处理文档级别任务
Encoder-Decoder
- T5(Text-to-Text Transfer Transformer)
- 思路:
- 模型:将所有 NLP 问题,都转化为 Text-to-Text 问题,用统一模型解决
- 输入:在输入数据前加上任务声明前缀(summarize、translate English to german…)这是 prompt 的前身?
- 输出:即使是需要输出连续值的任务,也输出文本,例如 STS-B(文本语义相似度任务)
- 结构:原始 Transformer
- 训练:
- 数据:C4,Colossal Clean Crawled Crpus, 公开爬取网页数据集
- 预训练:
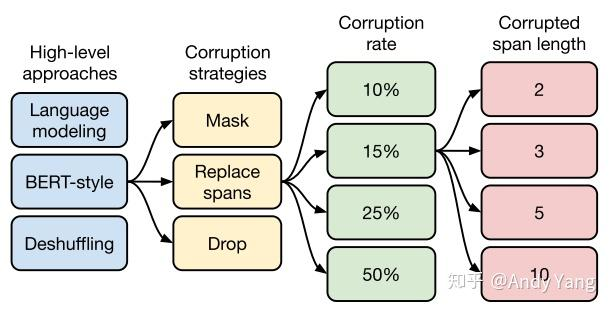
- 高层次方法:选择类似 BERT 的 MLM 任务,即破坏部分并还原
- 文本破坏方法:选择小段文本替换(而不是 token 替换)
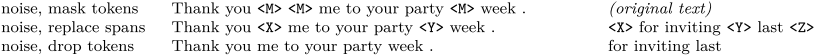
- 破坏占比:15%
- 小段文本替换的长度选择:3
- 规模:
- Small (60M):Encoder 和 Decoder 都只有 6 层,隐维度 512,8 头;
- Base (220M):相当于 Encoder 和 Decoder 都用 BERT-base;
- Large (770M):Encoder 和 Decoder 都用 BERT-large 设置,除了层数只用 12 层;
- 3B (Billion) /11B:层数都用 24 层,不同的是其中头数量和前向层的维度。 11B 达到 Sota,本质是数据量堆起来的
- 思路:
- 优点
- 适合做需要理解输入(即有条件)后的输出相关任务,如机器翻译,问答系统
- 缺点(与 decoder-only 相比)
- 需要训练两个模块,计算复杂度高
- Attention 容易退化为低秩矩阵,限制表达能力;在同等参数量下,泛化性能类似
Decoder-Only
- GPT 系列
- LLaMA 系列
- 优点:
- In-context Learning:Decoder 机构的 In-context Learning 能力更强,因为 Prompt 可以更直接的作用于 Decoder 的每一层参数,无需经过编码器的转换,微调的信号更强,使得 Decoder-Only 能够更准确的捕捉和利用输入序列的信息
- Attention:双向 Attention 的注意力矩阵容易退化为低秩状态;Causal Attention 的注意力矩阵是下三角阵,依然满秩,建模能力强,且具有隐式的位置编码功能
- 计算效率:支持一直复用 KV-cache,计算效率更高
- 泛化性:zero-shot 泛化性能更好,few-shot 能力更强