3 most important points
- BERT 与 Transformer 的主要区别在于只采用 Encoder,且将输入改为 [CLS]+句子 A(+[SEP]+句子 B+[SEP])的形式;预训练之后,相应输出能适应分类/回归/训练多种下游任务
- 输入 = token embedding + position embedding + segment embedding,其中 position embedding 可学习(提供位置的用处),与 Transformer 的固定函数 PE 不同
- BERT 没有在自注意力部分 mask,是双向模型,能用 MLM 任务较为准确的词义
5 thoughts
- 标准 BERT 含 12 个 Transformer 层,总参数量 110M,与 GPT1 相当
- MLM 任务中预训练与微调不匹配,影响有多大?
- 有提到“BERT 的 NSP 任务效果不明显”,我想这也许是拼接句子的初衷之一?没有达成?
- 其可学习 PE 存在长度上限,是限制 BERT 长文本能力的原因之一;当然拼接两个句子本身序列就很长,计算复杂度高。这个 PE 真的很有效吗?
Notes
任务
- 分类/回归:pooler output,由 CLS(分类标记 Classification Token,添加在输入序列的开头)输出,用作整个输入文本的表示
- Single Sentence Classification tasks 文本分类
- Sentence Pair Classification tasks 给定前提,推断假设是否成立
- 文本相似度判断(回归)
- 序列:sequence output
- 命名实体识别(NER) 识别特定含义的词语,如人名、地名等
- Cloze task 完形填空
- Standford Question Answering Dataset Task 按问题在文章里找答案的位置
结构
结构图
- BERT-base 包含 12 个 transformer 层(原始 transformer 6 个编码器 6 个解码器),每层多头注意力机制包含 12 个头,隐状态维度 768,总参数量 110M,与 GPT1 的参数量相当
- BERT-large 24 层,每层 16 个多头,隐状态维度 1024,总参数量 340M
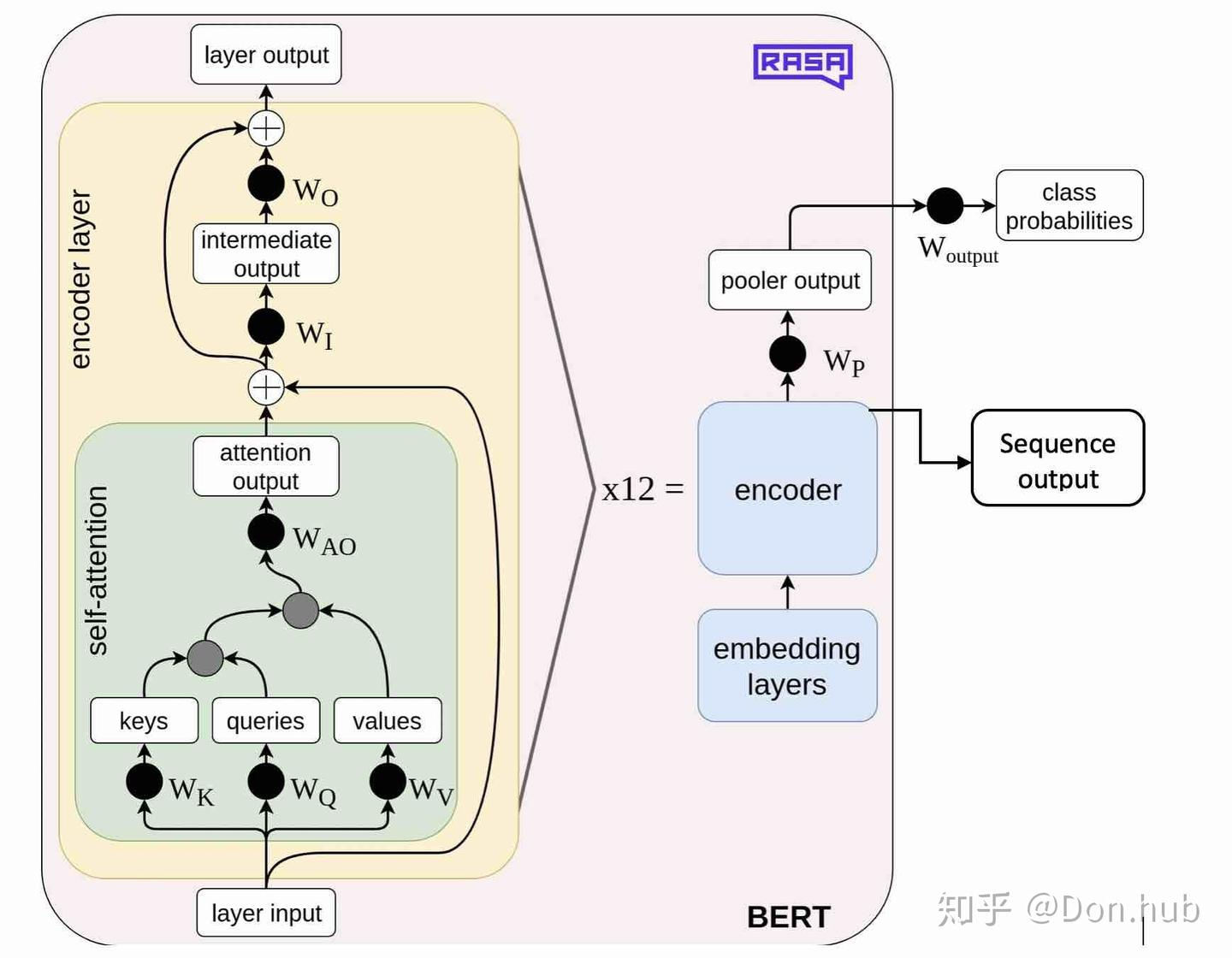
- 输入层:以下三者相加 先加后查找和先拼接后查找得到结果一致
- Token Embedding 词向量:更改为句子 A 和 B 拼接,[CLS]+句子 A+[SEP]+句子 B+[SEP]
- CLS:代表分类任务的特殊 token
- SEP:分隔符
- 句子 B 可以为空,此时为 [CLS]+句子 A
- Position Embedding 位置编码:
- 类似 word embedding 的方式,位置编码也是随机生成且可训练的,维度为
[seq_length, width],其中 seq_length 代表序列长度,width 代表每一个 token 对应的向量长度 - 优点:Transformer 的位置编码是一个固定值,因此只能标记位置,但是不能标记这个位置有什么用;BERT 的位置编码是可学习的 Embedding,因此不仅可以标记位置,还可以学习到这个位置有什么用
- 缺点:Embedding 长度有上限,即限制了序列长度
- 类似 word embedding 的方式,位置编码也是随机生成且可训练的,维度为
- Segment Embedding 分句:
- 0:[CLS]、句子 A、第一个[SEP]
- 1:句子 B、第二个[SEP]
- Token Embedding 词向量:更改为句子 A 和 B 拼接,[CLS]+句子 A+[SEP]+句子 B+[SEP]
- 中间层:与 Transformer Encoder 一致,但 self-attention 没有 mask,改造为双向
- 输出层:与 Transformer Encoder 一致
BERT 为什么采取双向模型?
传统的语言模型从左到右顺序考虑,限制了模型的能力;若将从左到右和从右到左两个模型融合,则参数量翻倍,且对于 QA 任务不合理,不如直接采用双向模型
因此 BERT 的 self-attention 没有 mask
训练
- 预训练
- 方式:无监督
- 数据:大量无标注的文本数据(8 亿单词图书预料库,25 亿单词英文维基百科语料库组成,约四倍于 GPT 的预训练语料)
- 任务:
- Mask Language Model (MLM)
- 类似于完形填空,将几个随机 token 替换为 [MASK]
- 问题:因为 fine-tuning 阶段中并没有 [MASK] token,所以导致了 pre-training 和 fine-tuning 的不匹配的情况
- 解决:特殊掩码方式,对于 15% token
- 80% 概率替换为 [MASK]
- 10% 概率替换为随机的 token
- 10% 概率是保持不变
- 损失:输出的 softmax 与真值的 cross-entropy
- Next sentence order (NSP)
- 预测两个句子是不是下一句的关系,使得模型懂得句子之间的关系
- 50%概率以上下句为输入,50%随机选择下半句
- 因拼接后长度随机,需要根据最大训练样本长度做额外处理,删除或补 0
- 输出是 pooler output
- Mask Language Model (MLM)
- 微调
- 根据下游任务添加输出层,添加的层从头训练
- 基于句子对的分类任务:
- MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,需要做的是去发掘前提和假设这两个句子对之间的交互信息。
- QQP:基于 Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。
- QNLI:用于判断文本是否包含问题的答案,类似于做阅读理解定位问题所在的段落。
- STS-B:预测两个句子的相似性,包括 5 个级别。
- MRPC:也是判断两个句子是否是等价的。
- RTE:类似于 MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。
- SWAG:从四个句子中选择为可能为前句下文的那个。
- 基于单个句子的分类任务
- SST-2:电影评价的情感分析。
- CoLA:句子语义判断,是否是可接受的(Acceptable)。
- 问答任务
- SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。
- 命名实体识别
- CoNLL-2003 NER:判断一个句子中的单词是不是 Person,Organization,Location,Miscellaneous 或者 other(无命名实体)。
对比
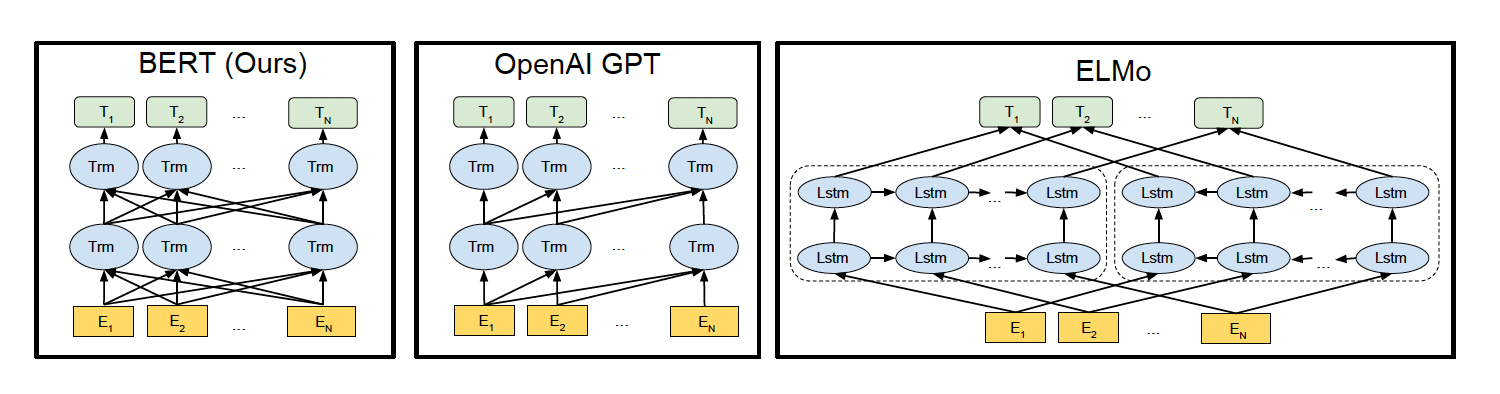
BERT/GPT/ELMO 的区别
如上图所示,图中的 Trm 代表的是 Transformer 层,E 代表的是 Token Embedding,即每一个输入的单词映射成的向量,T 代表的是模型输出的每个 Token 的特征向量表示。
- BERT 使用的是双向的 Transformer,OpenAI GPT 使用的是从左到右的 Transformer。ELMo 使用的是单独的从左到右和从右到左的 LSTM 拼接而成的特征。
- BERT 和 OpenAI GPT 是微调(fine-tuning)的方法,而 ELMo 是一个基于特征的方法。
从网络结构以及最后的实验效果来看,BERT 比 ELMo 效果好主要集中在以下几点原因:
- LSTM 抽取特征的能力远弱于 Transformer
- 拼接方式双向融合的特征融合能力偏弱
- BERT 的训练数据以及模型参数均多于 ELMo
- 优点
- BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。
- 相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。
- 缺点
- 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
- BERT 的 NSP 任务效果不明显,MLM 存在和下游任务 mismathch 的情况。
- BERT 对生成式任务和长序列建模支持不好。