3 most important points
- Diffusion Models 将扩散过程和逆扩散过程都建模为马尔科夫链,但经过推导,能够从初始跳跃至马尔科夫链上的任意时间步,无需逐步扩散,从而显著简化训练和采样计算
- Diffusion Models 的模型是噪声预测器,DDPM 采用了一个 U-Net 结构的 Autoencoder
- 通过重参数(引入一个随机变量)实现从高斯分布中采样这一步骤的梯度传播
5 thoughts
- 超参数 作为方差控制不同时间步的噪声强度,递增使得扩散初期图像保留主要语义结构,后期逐步向标准高斯收敛,保证整个分布平稳过渡
- 均值受方差约束确定,是因为将图视为高维度信号,需要保证过程中能量守恒,信号不会被放大或缩小
- 预测噪声而非均值能保持不同时间步上输出范围固定、梯度尺度一致,训练更稳定、收敛更快,且存在明确物理意义
- 逆扩散过程中的方差由超参数直接定义,是因为方差只影响采样的多样性,对训练目标影响极小;如果预测方差,会增加梯度计算复杂度,且效果没有明显提升
- 采样时添加噪声是为了保持生成过程随机性与多样性,否则只能生成单一样本
Notes
核心思想
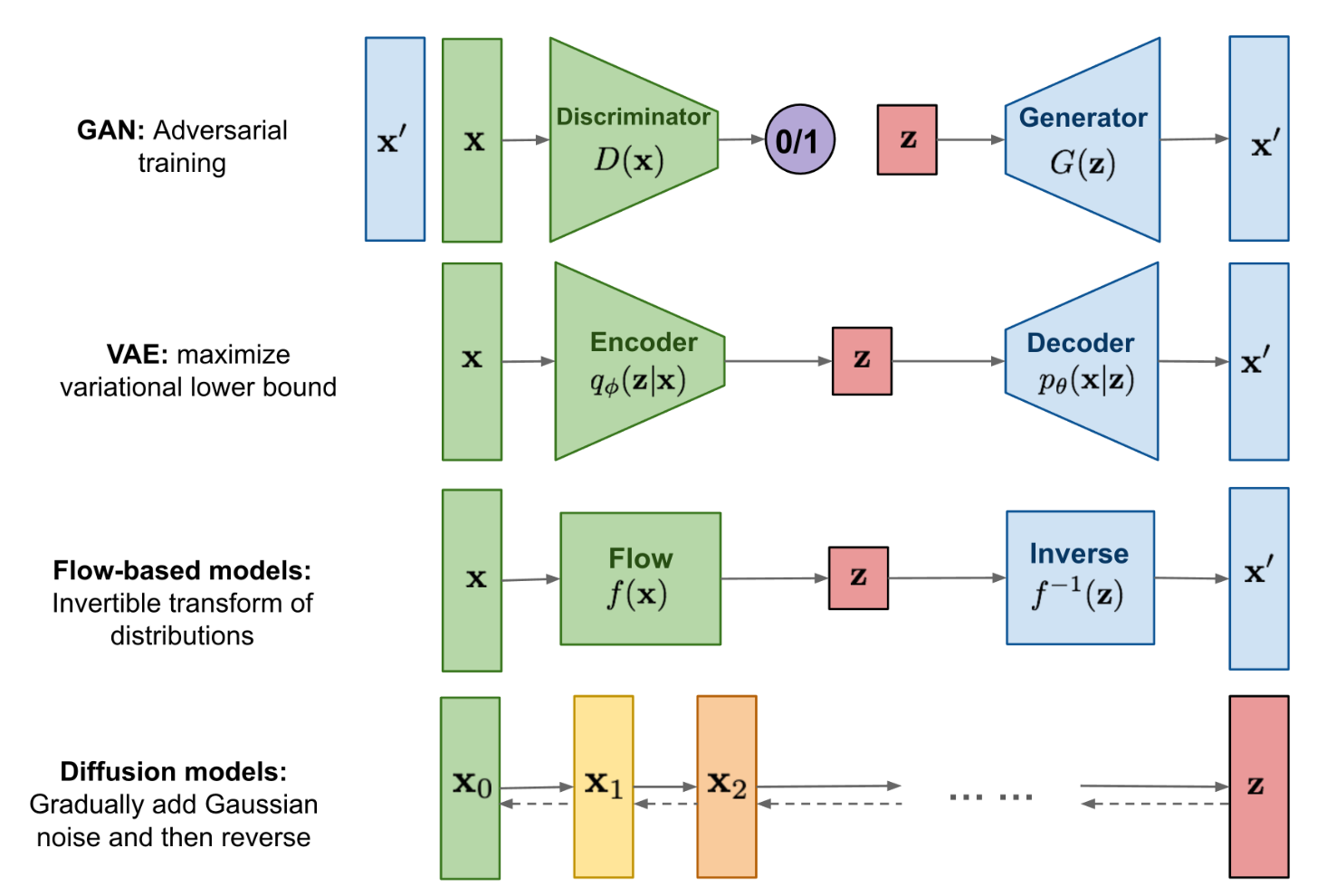
不同生成模型对比
- Diffusion models 和其他模型最大的区别是它的 latent code () 和原图是同尺寸大小的
- 设定:
- 图像空间:所有图像组成概率分布
- 训练集:从 中一个分布 中取出的随机样本
- 模型:在 中与 最接近的分布
- 原理:
- 扩散(前向过程):
- 每个时间步,在 上添加随机噪声,得到接近纯噪声的 ,使样本分布从 逐渐逼近标准高斯分布
- 该过程是一个马尔科夫链,由条件分布 定义,表示基于前一状态的现状态的概率
- 使用一系列的超参数 ( 随着 增大而增大)来进一步定义条件分布,用以控制马尔科夫链上每一步的大小,它们表示高斯分布的方差
- 最终:
- 逆扩散(逆向过程):
- 每个时间步,在从噪声分布 中采样的 上减去噪声生成 ,逐步逼近真实数据分布
- 该过程也是一个马尔科夫链,由后验分布 定义,该概率分布未知,因此使用模型 来近似它
- 未知情况下,使用 近似均值, 近似方差
- 最终:
- 扩散(前向过程):
为什么选择方差为超参数而不是均值?均值如何由方差取得?
- 直接定义方差 可控制加噪强度
- 图像可看作高维信号, 控制“保留多少旧能量”, 控制“加入多少新噪声能量”;
- 上述定义可以保证整个过程每一步的总能量是恒定的,这样信号不会被放大或缩小,只是噪声比例在逐渐上升。
为什么 是递增的?
- 如果 恒定,早期图像可能被过快破坏,模型难以学习;后期噪声太弱则去噪训练信号不足。
- 所以 通常递增(如线性或余弦调度),实现“先慢后快”的平滑加噪。
- 当 递增且较小(如线性增长到 0.02 左右),最终方差稳定收敛到 1,不会发散或塌缩
技巧
Info
这个板块讲解如何简化原理中复杂、难以实现的部分
- 在马尔科夫链中跳步
- 问题:
- 在扩散过程中,逐步计算耗时耗算力
- 解法:
- 令 ,并且 ,利用独立高斯随机变量的和的性质和尺度变换性质,展开 可以得到:\begin{align}x_t &= \sqrt{\alpha_t}x_{t-1} + \sqrt{1 - \alpha_t}\epsilon_{t-1} \quad \text{where } \epsilon_{t-1}, \epsilon_{t-2}, \cdots \sim \mathcal{N}(0, \mathbf{I})\\[6pt] &= \sqrt{\alpha_t\alpha_{t-1}}x_{t-2} + \sqrt{1 - \alpha_t\alpha_{t-1}}\bar{\epsilon}_{t-2} \quad \text{where } \bar{\epsilon}_{t-2} \text{ merges two Gaussians}\\[6pt] &= \cdots \\[6pt] &= \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}\end{align}
- 因此任意时刻的 满足:
- 问题:
- 重参数(reparameterization trick)
- 问题:
- 从某个分布中随机采样一个样本的过程无法反向传播梯度,而在逆扩散过程中,需要从高斯分布 中采样
- 解法:
- 用独立随机变量 引导随机性,采样可以写成:
- 因为 从模型中得到( 由超参数 给定),所以整个采样过程仍然梯度可导
- 问题:
为什么逆扩散过程中的方差可以直接定义?
理论上 是可学习的(比如 DDIM、Improved DDPM 都尝试学习它),因为真实的后验 的方差确实依赖于数据分布。
然而原始 DDPM 发现:即使把方差固定为常数(比如直接用 ),训练效果几乎不变。这是因为:
- 逆扩散的“随机性”主要由 决定;
- 方差只影响采样的多样性,对训练目标影响极小;
- 如果也去预测方差,梯度传播会更复杂,而且效果提升不明显。
- 均值的解析解
- 问题:
- 逆扩散过程中,均值 如何从模型中得到?
- 解法:
- 在知道 的情况下,考虑后验分布构成的
- 根据乘法定理和贝叶斯公式展开:\begin{align*}q(x_{t-1}|x_t, x_0) &= \frac{q(x_t, x_0, x_{t-1})}{q(x_t, x_0)} \\[6pt] &= \frac{q(x_0)q(x_{t-1}|x_0)q(x_t|x_{t-1}, x_0)}{q(x_0)q(x_t|x_0)} \\[6pt]&= q(x_t | x_{t-1}, x_0) \cdot \frac{q(x_{t-1} | x_0)}{q(x_t | x_0)}\end{align*}
- 由于 与 无关,所以都是已知的,根据高斯分布的概率密度函数展开,合并指数部分:
- 整理为与 相关的:
- 同时,后验分布可以直接写成:\begin{align} q (x_{t-1}|x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}(x_t, x_0), \tilde{\beta}_t \mathbf{I}) &\propto \exp\left( -\frac{(x - \tilde{\mu})^2}{2\tilde{\beta}_t^2} \right)\\ &=\exp\left( -\frac{1}{2} \left( \frac{1}{\tilde{\beta}_t^2} x^2 - \frac{2\tilde{\mu}}{\tilde{\beta}_t^2} x + \frac{\tilde{\mu}^2}{\tilde{\beta}_t^2} \right) \right)\end{align}
- 解方程组,把 和 都用 表示,代入得:
- 这样,就可以用模型 预测当前步噪声 ,再代入公式得到
- 问题:
为什么不直接预测均值?
如果直接预测 ,不同 的梯度尺度会严重不均:
- 早期( 小)时 仍接近 ,误差小
- 后期( 大)时 几乎是纯噪声,预测难度高,梯度极不稳定
预测噪声 后:
- 所有时间步都来自相同分布
- 模型输出范围固定,梯度尺度一致
- 可统一训练目标为简单的 L2 loss
同时:
- 预测有明确的物理意义(“识别图片中的噪声”),符合直觉
- 使模型能自然处理不同噪声强度(不同 )的输入,泛化更强
训练
Warning
由于完整的损失函数推导过于复杂,这里略过大部分过程
- 优化目标
- 使用极大似然估计求模型参数,即最大化模型预测分布的对数似然
- 从 Loss 下降的角度就是最小化负对数似然
- 与 VAE 类似,使用变分下界(VLB)也就是证据下界(ELBO)来优化负对数似然
关于 VLB
变分下界(Variational Lower Bound, VLB),也称为证据下界(ELBO),是用于近似优化难以直接计算的对数似然(如生成模型中的边缘似然 )的一种方法。通过引入一个可学习的近似后验分布 ,VLB 将负对数似然分解为一个可计算的下界和一个非负的 KL 散度项:
最大化 VLB 等价于最小化负对数似然的上界,从而间接提升模型对数据的拟合能力。
其中的 KL 散度项衡量两个分布之间的距离,为 0 的时候两个分布一致;所以这里是在拉近模型分布和后验分布的距离。
- 模型
- 不是直接预测 ,而是用模型 预测当前步噪声 ,再代入公式得到
- DDPM 采用了一个 U-Net 结构的 Autoencoder 作为
- 算法
- 采样
- 在训练集中采样
- 在常数 中采样一个
- 在高斯分布 中采样一个与图像大小相同的噪声
- 梯度下降,训练 :
- 直觉理解:将真实图片 和噪声 以一定比例混合在一起输入,同时输入混合比例 ,训练噪声预测器使得它的输出接近从高斯分布中采样出的 (能够认出混合在图片中的噪音)
- 采样
采样
- 在高斯分布 中采样一个与图像大小相同的噪声
- 当 :
- 在高斯分布 中采样一个与图像大小相同的噪声 ;在 时取
- 计算下一循环输入
- 返回
- 直觉理解:就是先识别 中的噪声,将它不断以一个比例从 中去除,乘一个常数,再加上一个噪声
采样过程为何又加噪声?
- 加上随机噪声 是为了保持采样多样性
- 逆扩散的每一步是随机采样而不是确定性去噪;如果不加 ,生成过程会退化为单一样本,不再具有“生成模型”性质
扩展
Todo
以下是很久以前的笔记,需要更新
Stable Diffusion
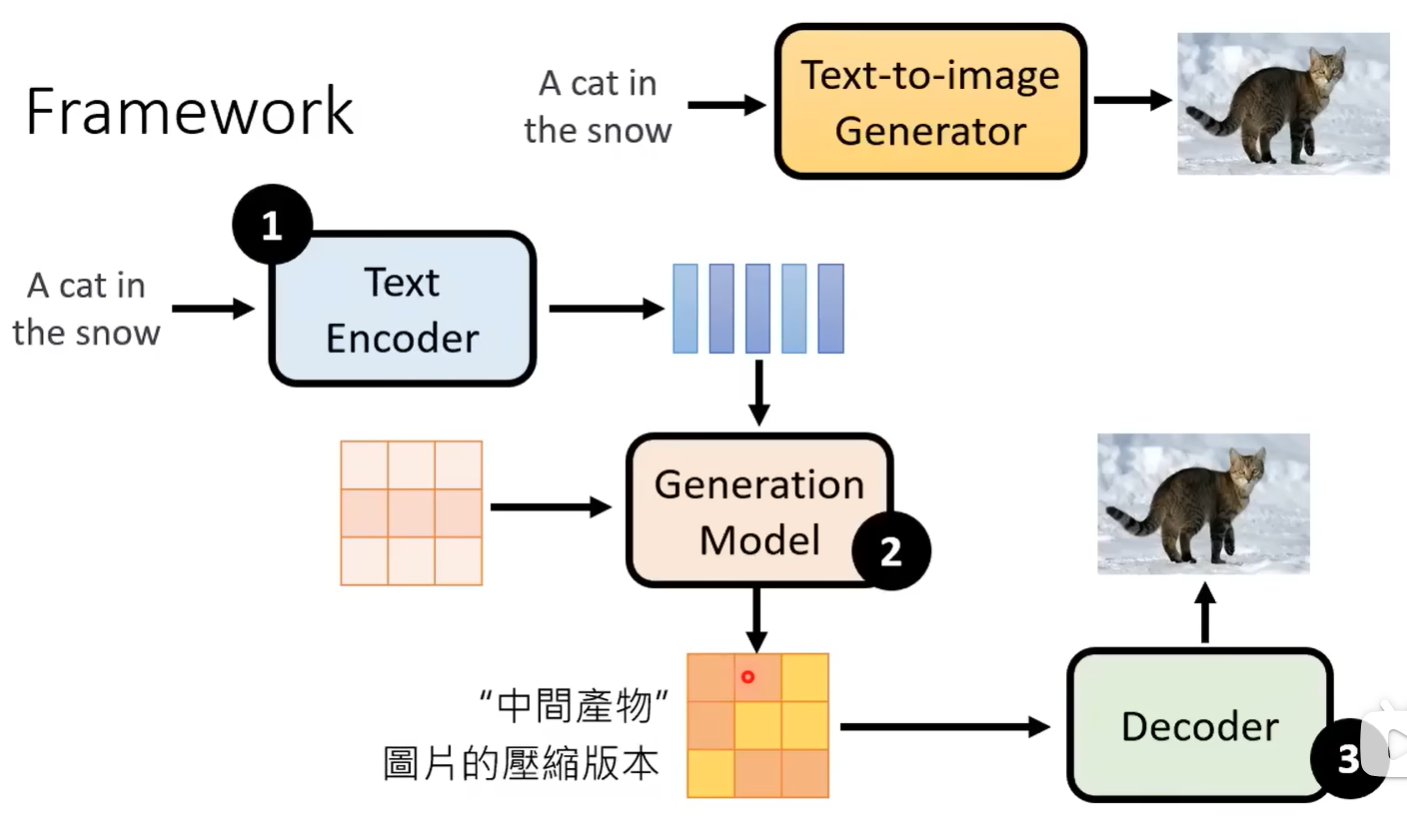
- Text Encoder
- 把文字描述转化为矩阵
- Generation Model
- 一般用 diffusion model,左侧那个矩阵应该是给定噪声
- Decoder
- 类 AE 的 decoder
VQ-Diffusion
论文名称:Vector Quantized Diffusion Model for Text-to-Image Synthesis 发表时间:2022.3.3 论文链接:https://arxiv.org/abs/2111.14822 论文代码:https://github.com/microsoft/VQ-Diffusion
- 动机:
- 分辨率过高的图像不利于 transformer 建模
- 结构:
- 使用 VQ-VAE 将图像压缩到离散的 codebook 空间
- 在 codebook 中 diffusion:引入 mask & replace
- 加噪声:随机 mask 一个 code 或者 replace 成另外一个 code,这样就能把原 code 变成一个随机噪声向量
- 形成概率转移矩阵 ,有
- :code 保持原样的概率
- :replace 的概率
- :mask 的概率
- 利用 transformer 网络把 code 噪声和文本信息 decode 成原本的 code
- 经由 decoder 恢复到原本的空间中
- 指标:
- FID:把真实图像和生成图像输入到训练好的 CNN 分类器中,如果两组的 representation 越接近,效果就越好;假设 representation 都是高斯分布,得到他们之间的 FID 也就是 frechet distance。这个指标越小越好。但是需要采样大量样本(例如 10K)来进行评估。(真实性评估)
- CLIP:Contrastive Language-Image Pre-Training,由 text encoder 和 image encoder 组成。训练好这个模型,把图像和与其对应的文字输入进去,编码出来的向量越近越好。(文本相近性评估)